
When people hear "LLM in production," they usually think "expensive infrastructure and high API costs." But what if I told you we built an AI-powered assignment aggregator that can process thousands of messages daily for just $5 per month?
We built a tool that helps Singapore tutors find relevant assignments by automatically monitoring and categorizing opportunities from 10+ Telegram channels. Here's how we architected an LLM application that scales on a minimal budget.

The Problem: Telegram Channel Chaos
Singapore's tutoring market is bustling, but finding the right assignments is painful. Tutors subscribe to dozens of Telegram channels where agencies post opportunities, but most messages aren't relevant to what they actually teach. Good assignments get buried in noise, and manually sifting through hundreds of daily messages is exhausting.
We needed a system that could:
- Monitor multiple channels continuously
- Extract structured data from loosely formatted messages
- Filter and categorize assignments intelligently
- Present everything in a clean, searchable interface
System Architecture: One Worker, Multiple Roles
Every 15 minutes, a single Cloudflare Worker orchestrates a three-step process:
- Data Collection: Calls Telegram APIs to fetch the latest messages from tracked channels
- Storage & Queuing: Adds each new message to our D1 database and pushes it into a Cloudflare Queue
- AI Processing: Picks up messages from the queue and runs them through an LLM for extraction
The beauty of this approach is its simplicity. The same Worker handles our backend API, cron scheduling, and queue processing—no orchestration complexity, no multiple services to maintain. Just one serverless function that scales automatically.
By using Cloudflare Queues (available on their $5/month paid plan) to space out our LLM requests, we stay well within Gemma's rate limits while processing hundreds of messages daily. This is our only infrastructure cost, and the queue functionality is essential for reliable processing.
LLM Extraction: Small Model, Big Impact
For the AI component, we chose Google's Gemma model. While smaller than GPT-4 or Claude, it's surprisingly capable for structured extraction tasks.
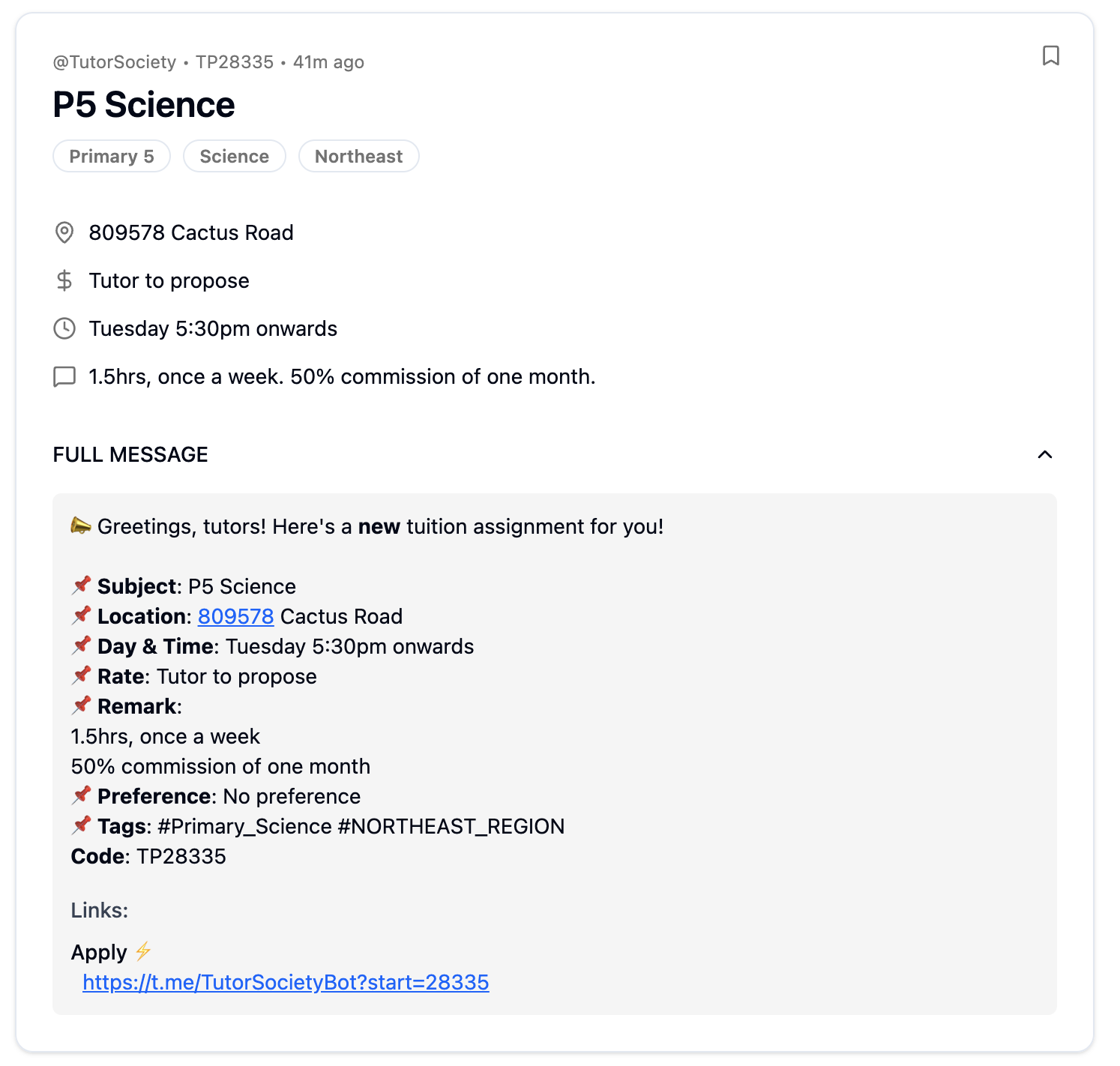
Our extraction process handles:
- Location: e.g. "Bukit Timah area"
- Rate: e.g. "$30/hr" or "$120 for 4 sessions"
- Schedule: e.g. "Weekdays after 6pm"
- Additional remarks: e.g. "Own transport needed" and similar requirements
- Smart tagging: Automatically adds searchable tags like "primary3", "science", "north"
The key insight is keeping extractions simple rather than trying to normalize everything. For location, we extract the raw text and add broad geographic tags instead of trying to standardize addresses—this makes the system much more robust to LLM mistakes while still enabling effective filtering.
Prompt Engineering That Works
The prompt design was straightforward. We had Claude generate a base prompt from sample messages and our desired output format. When the initial results were too verbose, a simple addition—"DO NOT use new lines, write in short sentences"—fixed the formatting perfectly.
The model handles real-world complexity remarkably well:
- Messages containing multiple assignments
- Informational content mixed with actual opportunities
- Various formatting styles across different agencies
- Reposted or forwarded content
Why This Architecture Works For Us
-
Simplified Deployment: Everything runs on Cloudflare's edge network. No containers, no server management, no scaling concerns at our current volume.
-
Small Models Can Be Effective: The key isn't using the biggest model—it's designing the system to be robust to LLM mistakes. By basing the filters on tags instead of the extracted raw data, we reduce the impact of extraction errors on the overall system.
-
Controlled Processing: Cloudflare Queues made it easy to configure workers to consume jobs at a slower rate, preventing API rate limit issues.
-
Cost Efficiency: At $5/month total infrastructure cost, we can validate ideas quickly without significant upfront investment.
What's Next
This architecture lets us spin up LLM-enabled apps that handle reasonable workloads, allowing us to validate ideas quickly and cost-effectively. As we grow, it'll be interesting to see how this simple foundation needs to evolve to handle increased complexity and user load.
Try out our assignment aggregator at tutoroapp.com. If you know any tutors in Singapore, send them our way!